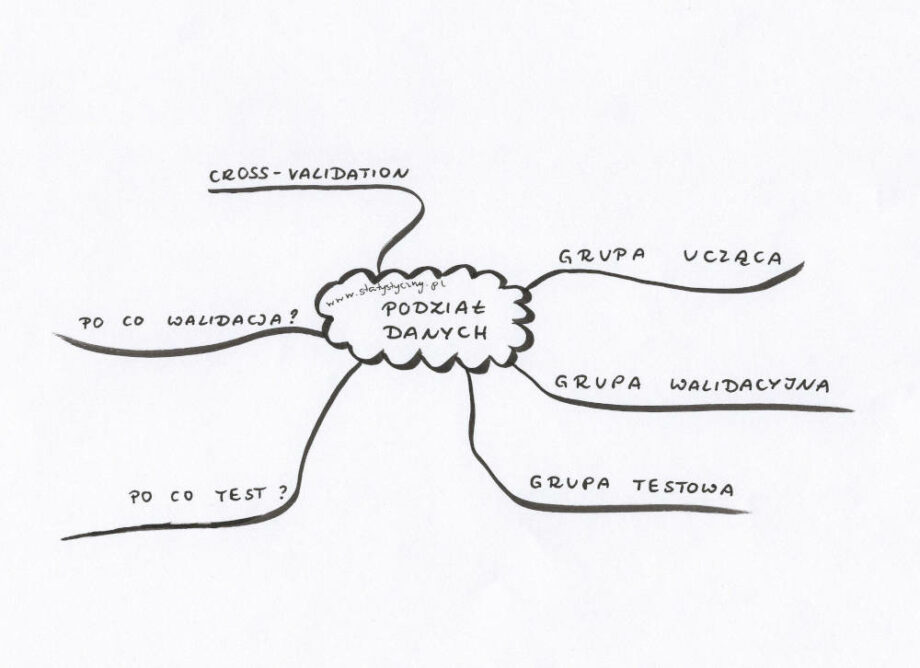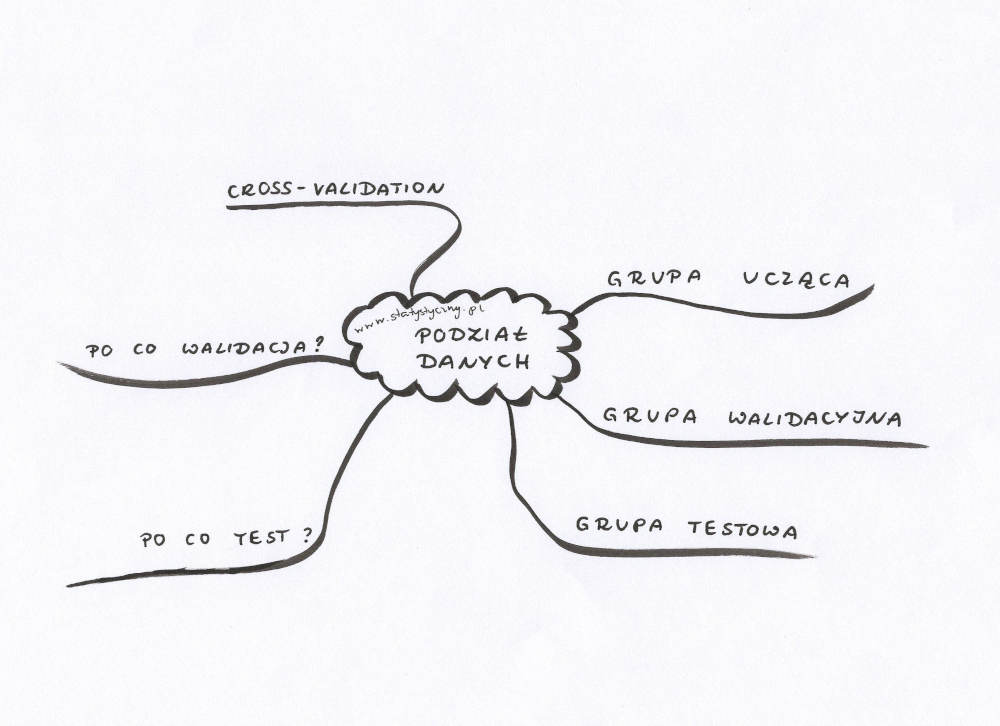
Cofnijmy się o jeden kroczek. Bo napisałam już ogólnie o machine learning. Napisałam również o klasyfikacji tekstu. Nie wspomniałam jednak ani słowem czym jest grupa ucząca, walidacyjna i testowa. A to przecież jedna z podstawowych informacji, które warto zrozumieć, kiedy zabieramy się za tematykę machine learning. Zwłaszcza, że przyda się nie tylko w przypadku klasyfikacji.
Podział na grupę uczącą, walidacyną i testową
Grupa ucząca – to taki zestaw danych, który używamy do nauki algorytmu. Na podstawie tych danych model uczy się odpowiednio klasyfikować, buduje wszelkie zależności. Można powiedzieć, że przewiduje możliwe wyniki i podejmuje decyzje na podstawie przekazanych mu danych.
Grupa walidacyjna jest to taki zbiór danych, którego używamy do przeprowadzenia nieobciążonego testu modelu, który przeszkoliliśmy na danych treningowych (uczących). Test ten przeprowadzamy podczas wyboru modelu albo dobierając zestaw hiperparametrów. Ważnym jest, żeby dane zawarte w zbiorze walidacyjnym nie były używane wcześniej do nauki modelu, ponieważ nie będą wtedy nadawać się do obiektywnego, nieobciążonego testowania.
Spotkałam się również z nazwą „development set” lub „dev set”. Podkreśla ona, że zestaw danych walidacyjnych służy do testowania wyników podczas doboru modelu czy hiperparametrów na etapie rozwoju wybranego algorytmu.
Grupa testowa – kiedy już wybraliśmy model, wybraliśmy hiperparametry, to nadchodzi czas na przetestowanie wszystkiego danymi z grupy testowej. Jest bardzo ważne, by dane te nie były wcześniej używane do uczenia czy walidacji modelu, ponieważ chcemy wiedzieć, jak wybrany algorytm sprawdza się na danych, z którymi nigdy wcześniej nie miał do czynienia.
Zestaw testowy powinien spełniać tak zwany „złoty standard”, czyli być idealnie przygotowanym, bez jakichkolwiek błędów. Jest używany tylko raz, na samym końcu, kiedy chcemy sprawdzić, jak zadziałały nasze powyżej wspomniane kroki – polegające na uczeniu i walidacji.
Konkursy machine learning
Warto tu może dodać, że istnieje możliwość wzięcia udziału w konkursach, które polegają na przygotowaniu jak najlepszego modelu machine learning dla określonego zestawu danych (na przykład na platformie kaggle). Dane opublikowane, to powinna być nasza grupa ucząca i walidacyjna. Możemy się spodziewać, że dane do testowania będą zupełnie nowe. Nie zobaczymy ich w trakcie trwania konkursu. Dopiero na koniec wszystkie wyniki zostaną za pomocą tych danych sprawdzone i jury konkursu będzie mogło podjąć decyzję, który model najlepiej zrealizował postawione przed uczestnikami zadanie.
Po co testować model?
Może zacznijmy od pytania, po co w ogóle testować działanie algorytmu. Czy nie lepiej użyć wszystkich danych do nauki i wtedy będzie najlepiej przeszkolony? Najkrótsza odpowiedź brzmi „nie”. Model możemy wtedy przetrenować i będzie idealnie przewidywać… ale tylko to, czego się już nauczył. Znajdzie wszystkie możliwe zależności (niektóre losowe), perfekcyjnie dopasuje wyniki do otrzymanych danych. A jak tylko pojawi się nowy przykład, którego nie było w grupie uczącej, to okaże się, że model nie wie, jak sobie z nim poradzić. Proponuję zobaczyć to na przykładzie.
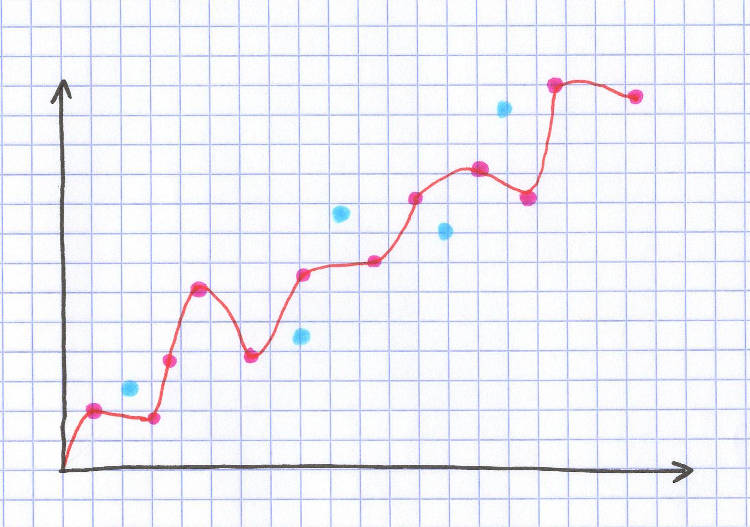
Proszę, jakie idealne dopasowanie modelu. Przechodzi dokładnie przez każdy punkt ze zbioru uczącego (czerwone kropki). Dokładność 100%. Ale kiedy spojrzymy na zbiór testowy (niebieskie kropki), to już się okazuje, że nie jest tak idealnie. Kropki są oddalone od idealnie wyuczonej linii. I po to jest zbiór testowy, żeby właśnie takiego przeuczenia uniknąć. Model nie może być dostosowany tylko i wyłącznie do danych, na których się uczy, bo każda nowa wartość go zaskoczy.
Dlaczego walidacja?
Używanie osobno grupy uczącej, walidującej i testowej jest szczególnie ważne, kiedy pracujemy z modelami, które zawierają wiele parametrów i potencjalnych hiperparametrów. Jeśli chcemy wybrać najlepszy możliwy model i najlepsze dane, to musimy bardzo uważać, żeby nie doprowadzić do wspomnianego przed chwilą nadmiernego dopasowania modelu do danych (ang. overfitting). Im więcej modeli, hiperparametrów i innych opcji chcemy testować, tym większy zestaw do walidacji nam się przyda. Właśnie po to, żeby uniknąć tego idealnego dopasowania wyłącznie do zestawu uczącego.
Zdarzają się modele, które mają bardzo mało hiperparametrów do optymalizacji. Zdarzają się sytuacje, kiedy z góry wiemy, jakiego modelu będziemy używać. Wtedy można sobie pozwolić na wykorzystanie tylko dwóch zestawów danych – uczącego i testującego. Przy czym należy zrobić to świadomie, mając na uwadze wszelkie możliwe konsekwencje wyboru.
train_test_split
Gdybyśmy chcieli użyć wyłącznie grupy uczącej i testowej, to w pythonowym scikit learn mamy taką bardzo prostą funkcję train_test_split. Tak jak nazwa mówi, dzieli nam zbiór na zbiór danych uczących i testujących (bez grupy walidującej). Robi to losowo (jest opcja wyboru odpowiedniego random state). Można odpowiednio dobrać proporcję grupy testowej.
sklearn.model_selection.train_test_split(*arrays, **options)
Przykład
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Powyższy przykład przygotuje nam podział na zbiór uczący i testowy , gdzie dane testowe będą stanowić 1/3 wszystkich danych. Wybrany jest również random state. Kiedy warto wybierać random state? Jeśli wiemy, że będziemy dany skrypt uruchamiać kilka razy, testować różne modele albo chcemy nad czymś pracować w większym zespole analityków. Pozwala to na zachowanie porównywalności pomiędzy poszczególnymi uruchomieniami modelu.
Cross-validation
Myślę, że w tym miejscu warto też wspomnieć o możliwości wykorzystania walidacji krzyżowej, czyli cross-validation. Najczęściej spotkamy się chyba z pojęciem K-krotnej walidacji. Mamy wtedy do czynienia z podziałem zaobserwowanych wartości na K podzbiorów. I po kolei każdy z tych podzbiorów jest traktowany jako zbiór walidacyjny, do testowania modelu. Pozstałe K-1 zbiorów w tym przypadku pełnią rolę zbioru uczącego. Jak już przeprowadzimy K analiz, to bierzemy wszystkie rezultaty. Następnie albo są one uśredniane albo w inny sposób łączone w celu uzyskania jednego ostatecznego wyniku.
Przy czym nawet jeśli korzystamy z opcji walidacji krzyżowej, to jest przyjęte, że warto mieć „odłożony na bok” zbiór danych do ostatecznego testowania modelu. Czyli oprócz walidacji nadal testujemy. I to zupełnie niezależnymi danymi.
Podsumowanie
Mam nadzieję, że teraz już wiecie, do czego służy grupa ucząca, walidująca i testowa. Mam nadzieję, że nie zaskoczy Was temat walidacji krzyżowej. I że poradzicie sobie z podziałem swoich danych na odpowiednie grupy. A gdybyście mieli jakieś pytania, to śmiało piszcie w komentarzach tutaj albo na facebooku.
Droga Czytelniczko! Drogi Czytelniku!
Dziękuję, że przeczytałaś/przeczytałeś mój artykuł. Mam nadzieję, że spełnił Twoje oczekiwania. Jeśli chcesz się podzielić swoimi przemyśleniami, to napisz do mnie na adres [email protected] albo znajdź mnie na Facebooku.
Zapraszam Cię również do zapoznania się ze spisem treści (staram się go aktualizować, choć nie zawsze to wychodzi) – jeśli lubisz statystykę, to na pewno znajdziesz coś do poczytania.
A jeśli w ramach podziękowania za ten wpis zechcesz zaprosić mnie na przysłowiową “wirtualną kawę”, to będę niezwykle zobowiązana. Co prawda kawy raczej nie pijam, ale kubek dobrej herbaty – z prawdziwą przyjemnością. A ponieważ w każdy artykuł wsadzam mnóstwo serducha i swojego wysiłku, to tym bardziej poczuję się doceniona.

Pozdrawiam Cię serdecznie i życzę miłego dnia!
Krystyna Piątkowska