Machine learning (tłumaczone na język polski jako „uczenie maszynowe”), to temat, który staje się z dnia na dzień coraz bardziej popularny. Nie ukrywam, że sama przyglądam się z rosnącym zainteresowaniem. A ponieważ gdzieś tam u źródeł machine learning leży statystyka, to myślę, że blog statystyczny jest dobrym miejscem, aby podzielić się z Wami również informacjami na ten temat.
Jeśli czytacie statystycznego od jakiegoś czasu, to wiecie już, że lubię choć trochę poczytać o tym, co dzieje się w nauce właśnie teraz. To dzięki temu powstał między innymi wpis o datazaurusie. I mam nadzieję, że również temat machine learning przyniesie nam dużo bieżących ciekawostek.
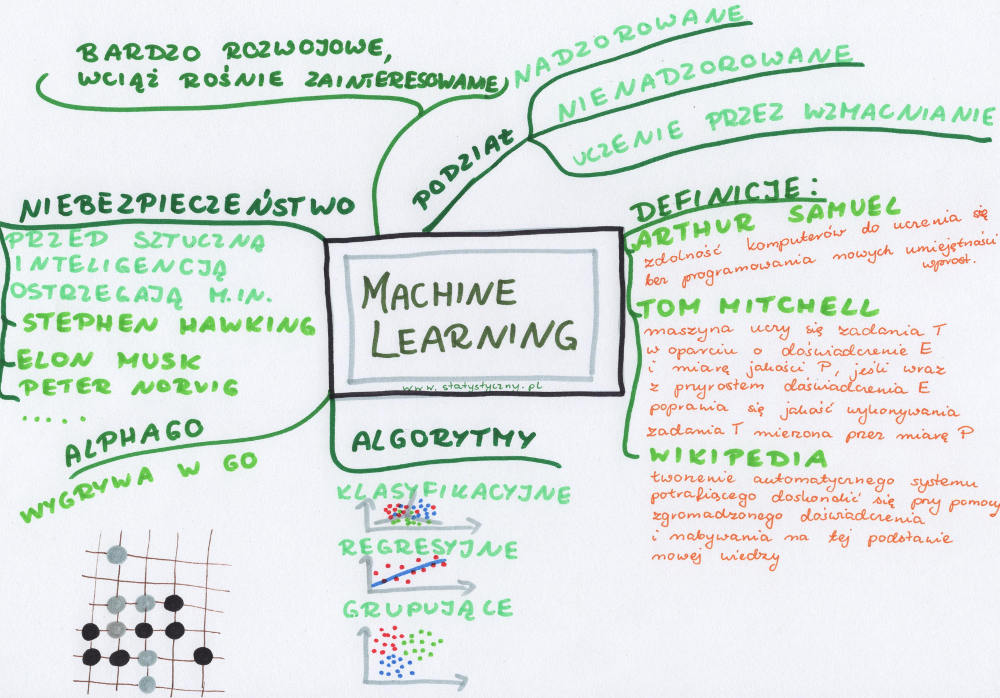
Machine learning – co to jest?
Wróćmy jednak do podstaw. Co to w ogóle jest machine learning? I tutaj Was może zaskoczę. Nie ma jednej słusznej definicji. Gdzie się nie spojrzy, tam każdy definiuje uczenie maszynowe po swojemu. Chodzi jednakowoż o to, żeby komputery były w stanie wykonywać zadania, do których nie zostały konkretnie zaprogramowane. Czyli na podstawie otrzymanych danych samodzielnie znajdywały rozwiązania. My przekazujemy informacje, a komputer na ich podstawie wyciąga wnioski.
Machine learning – kilka definicji
Nazwę machine learning wymyślił Arthur Samuel w 1959 roku i określił tymi słowami zdolność komputerów do uczenia się bez programowania nowych umiejętności wprost (ang. Field of study that gives computers the ability to learn without being explicitly programmed).
Drugą bardzo znaną definicję machine learning zaproponował Tom Mitchell. Według niego mówimy, że maszyna uczy się zadania T w oparciu o doświadczenie E i miarę jakości P, jeśli wraz z przyrostem doświadczenia E poprawia się jakość wykonywania zadania T mierzona przez miarę P.
Na wikipedii przeczytamy natomiast, że uczenie maszynowe to nauka interdyscyplinarna ze szczególnym uwzględnieniem takich dziedzin jak informatyka, robotyka i statystyka. Głównym celem jest praktyczne zastosowanie dokonań w dziedzinie sztucznej inteligencji do stworzenia automatycznego systemu potrafiącego doskonalić się przy pomocy zgromadzonego doświadczenia (czyli danych) i nabywania na tej podstawie nowej wiedzy.
Mam nadzieję, że na podstawie tych trzech powyższych definicji umiecie sobie sami wyobrazić, czym właściwie jest machine learning.
Uczenie nadzorowane i nienadzorowane oraz przez wzmocnienie
Machine learning możemy podzielić według różnych kryteriów. Ze względu na rodzaj dostarczonych przykładów i informacji, jakie one zawierają, dzielimy na uczenie nadzorowane i nienadzorowane. Niektórzy wspominają tu kolejną metodę – uczenie przez wzmacnianie.
Uczenie nadzorowane (ang. supervised learning) to takie, kiedy zbiór danych dostarczany maszynie do nauki zawiera również oczekiwaną odpowiedź. Na przykład zdjęcia różnych kwiatków, a do tego nazwa każdego z nich. Albo zestaw maili z informacją, który z nich to spam a który nie. Dzięki takiemu nauczaniu oczekujemy, że po pokazaniu zdjęcia, którego wcześniej nie było w zbiorze danych, dowiemy się, jaki jest to kwiatek (wcześniej musiały być inne zdjęcia tego kwiatka, żeby komputer miał się skąd tego nauczyć). A nowy mail trafi albo do skrzynki odbiorczej albo do spamu.
Uczenie nienadzorowane (ang. unsupervised learning) to takie, kiedy nie dostarczamy żadnych odpowiedzi, tylko zestaw danych. Na przykład dostarczamy zdjęcia różnych kwiatków, ale nie mamy na ich temat żadnych więcej informacji. Oczekujemy, że zostaną podzielone na jakieś grupy i każde nowe zdjęcie trafi do grupy, gdzie znajdują się kwiatki do niego podobne. Co to znaczy „podobne”? Wybór należy do maszyny uczącej się. Zwykle na początku podaje się informację, na ile grup byśmy chcieli podzielić nasze dane.
Uczenie przez wzmacnianie (ang. reinforcement learning) to takie, kiedy system działa w środowisku zupełnie nieznanym. Brak jest zarówno określonych danych wejściowych jak i wyjściowych. Jedyną informacją, jaką otrzymuje maszyna ucząca się jest tzw. sygnał wzmocnienia. Sygnał ten może być albo pozytywny (nagroda) albo negatywny (kara). Metodę tę można inaczej nazwać metodą prób i błędów. Przykładem może być gra w nową grę, której reguł nie znamy. Po skończonej grze dowiadujemy się, czy wygraliśmy, czy przegraliśmy (nagroda/kara). W kolejnych grach powinno iść coraz lepiej.
(Tu się nieśmiało przyznam, że czasem sama stosuję tę metodę (czyli uczenie przez wzmacnianie), jak gram na komórce w nową grę i nie chce mi się przeczytać instrukcji. Zwykle po kilku próbach udaje mi się w przybliżeniu przynajmniej zrozumieć, o co chodzi.)
Podstawowy podział algorytmów machine learning
Algorytmy klasyfikacyjne – to takie algorytmy, które pozwalają przypisać dane do odpowiednich kategorii. Przykład najbardziej znany, to podział maili na spam i nie-spam. Oprócz tego rozpoznawanie kwiatków po wyglądzie albo ręcznie napisanych cyferek. Jeśli przypisujemy dane do dwóch kategorii, to mamy do czynienia z klasyfikacją dwuklasową (ang. two-class classification). Jeśli etykiet jest więcej, to mówimy o klasyfikacji wieloklasowej (ang. multiclass classification).
Algorytmy regresyjne – to zupełnie jak w tekście o regresji liniowej. Mamy dane wejściowe (np. wielkość czekolady, zawartość kakao, producent itp.), a oczekujemy, że algorytm pomoże nam przewidywać cenę takiej czekolady (oczekujemy tu wartości ciągłych, a nie dyskretnych, w przeciwieństwie do klasyfikacji).
Algorytmy grupujące – zadaniem tych algorytmów jest podzielenie danych na grupy (klastry) na podstawie podobieństw – np. klientów banku o podobnej historii.
Są też różne inne algorytmy, ale mniej znane i chwilowo nie będę ich opisywać.
Machine learning a gry
Kiedyś grałam dość dużo w go. Jeździłam między innymi na turnieje, zdobywałam kolejne stopnie wtajemniczenia, ale równocześnie brałam udział w wielu akcjach zachęcających ludzi do tej gry. Często słyszałam zdanie”jeśli szachy są królem gier, to go jest ich cesarzem”. Zwykle po tym wspominano jak to Kasparow przegrał w szachy z komputerem. Go było wtedy symbolem gry, która daje tak szerokie możliwości, że żaden komputer nie jest w stanie pokonać człowieka. Ze śmiechem była wspominana nagroda (milion dolarów) dla autora programu, który wygra z mistrzem.
Tyle tylko, że w 2016 roku stało się to nieaktualne. Zespół DeepMind stworzył program AlphaGo, który pokonał Lee Sedola – jednego z najlepszych graczy w go na świecie. AlphaGo nie opierał się na napisanym przez człowieka algorytmie („jeśli przeciwnik zagra to, to najlepiej zagrać tamto”). Nie było takiej możliwości, bo w go zbyt dużo różnych ruchów jest do wyboru (w go jest więcej kombinacji niż atomów we wszechświecie). Program więc uczył się poprzez przykłady. Analizował miliony rozegranych wcześniej gier, grał „sam ze sobą”. I w końcu zwyciężył tam, gdzie przez wiele lat wydawało się to nierealne. Grę śledziło mnóstwo osób na całym świecie – nie tylko graczy go, ale również osób zainteresowanych rozwojem sztucznej inteligencji. Została uznana za jedno z przełomowych wydarzeń w historii machine learning.
Czy należy bać się sztucznej inteligencji?
Niby pomaga i ułatwia nam życie. Coraz więcej jej dookoła. Samochody nie potrzebują kierowców, lekarz jest wspomagany przy stawianiu diagnozy, maile same dzielą się na spam i nie-spam, dostajemy dopasowane rekomendacje – co przeczytać albo obejrzeć. Machine learning coraz bardziej zadomawia się w naszym codziennym życiu i w większości przypadków nawet nie wiemy, że z niego korzystamy. Wydaje się, że postęp jest nieunikniony. Że dzięki temu będzie tylko lepiej. Nie ukrywam jednak, że budzi we mnie trochę strachu. Może zbyt dużo naczytałam się książek science-fiction? Ale dlaczego w takim razie ostrzegali przed nią również Elon Musk czy (niestety niedawno zmarły) Stephen Hawking?
mapa myśli: machine learning
Droga Czytelniczko! Drogi Czytelniku!
Dziękuję, że przeczytałaś/przeczytałeś mój artykuł. Mam nadzieję, że spełnił Twoje oczekiwania. Jeśli chcesz się podzielić swoimi przemyśleniami, to napisz do mnie na adres [email protected] albo znajdź mnie na Facebooku.
Zapraszam Cię również do zapoznania się ze spisem treści (staram się go aktualizować, choć nie zawsze to wychodzi) – jeśli lubisz statystykę, to na pewno znajdziesz coś do poczytania.
A jeśli w ramach podziękowania za ten wpis zechcesz zaprosić mnie na przysłowiową “wirtualną kawę”, to będę niezwykle zobowiązana. Co prawda kawy raczej nie pijam, ale kubek dobrej herbaty – z prawdziwą przyjemnością. A ponieważ w każdy artykuł wsadzam mnóstwo serducha i swojego wysiłku, to tym bardziej poczuję się doceniona.

Pozdrawiam Cię serdecznie i życzę miłego dnia!
Krystyna Piątkowska